This week’s model release features DBRX, a state-of-the-art large language model (LLM) developed by Databricks. With demonstrated strength in programming and coding tasks, DBRX is adept at handling specialized topics and writing specific algorithms in languages like Python. It can also be used for text completion tasks and few-turn interactions. DBRX long-context abilities can be used in RAG systems to enhance accuracy and fidelity.
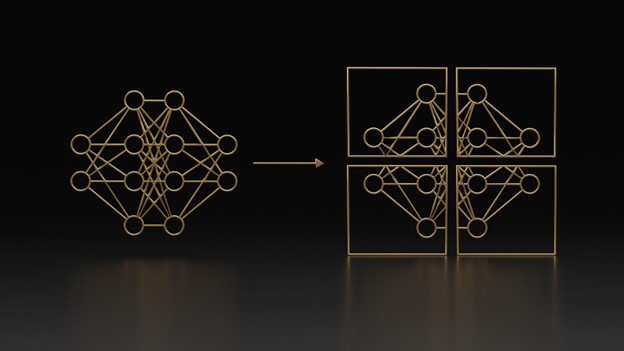
The model’s use of fine-grained mixture of experts (MoE) architecture is a key feature that distinguishes it from other models. MoE architecture excels in handling complex tasks by leveraging a collection of specialized “expert” networks. During inference, MoE dynamically selects and combines the outputs of these expert networks based on the input data, using a learned gating mechanism.
This gating mechanism routes different parts of the input data to the most relevant expert networks, enabling MoE to effectively harness their collective expertise and generate superior predictions or outputs. By adaptively coordinating the contributions of its constituent networks, MoE achieves exceptional performance on diverse tasks while efficiently utilizing computational resources.
The DBRX fine-grained MoE approach uses more experts that are individually smaller, resulting in improved performance and efficiency. The architecture involves a total of 132 billion parameters, with 36 billion active parameters at any given time, managed through the use of 16 experts, of which four are activated for each token processed.

DBRX is optimized for latency and throughput using NVIDIA TensorRT-LLM. It now joins over two dozen popular AI models that are supported by NVIDIA NIM, a microservice designed to simplify the deployment of performance-optimized NVIDIA AI Foundation models and custom models. NIM enables 10x to 100x more enterprise application developers to contribute to AI transformations.
NVIDIA is working with leading model builders to support their models on a fully accelerated stack. These include popular models like Llama3-70B, Llama3-8B, Gemma 2B, Mixtral 8X22B, and many more. Visit ai.nvidia.com to experience, customize, and deploy these models in enterprise applications.
Get started with DBRX
To get started with DBRX, visit build.nvidia.com. With free NVIDIA cloud credits, you can start testing the model at scale and build a proof of concept (POC) by connecting your application on the NVIDIA-hosted API endpoint running on a fully accelerated stack.